
Column-level Lineage Comes to DataHub
Lineage
Data
DataHub
Data Lineage
Metadata


Lineage
Data
DataHub
Data Lineage
Metadata

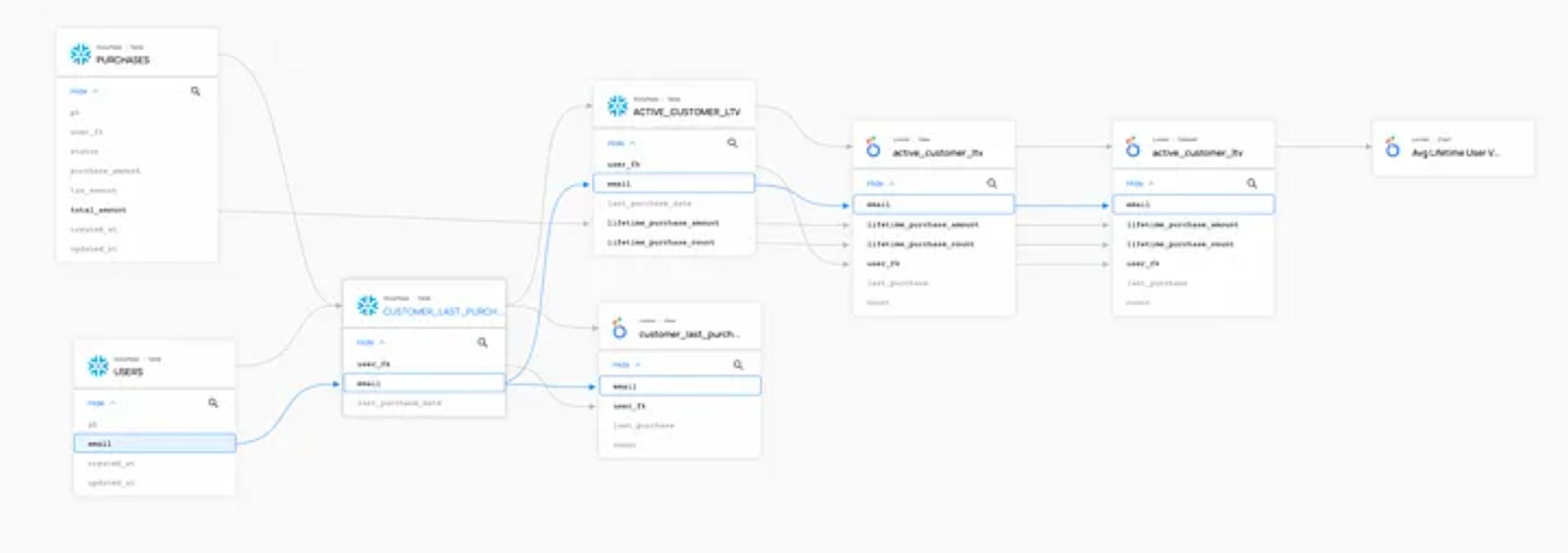
With DataHub, we’re committed to helping our users to discover, trust and act on the data in their organizations. Upstream and downstream lineage, i.e., understanding where a data product comes from and how it’s used, is critical to making this happen.
And that’s why we couldn’t be more excited to have made column-level lineage, one of DataHub’s most requested features, happen!
About Lineage in DataHub
When we were building DataHub’s Lineage feature, we wanted to provide end-to-end visibility of the production, transformation, and consumption of an organization’s data — irrespective of the platforms it is being curated through. To this end, lineage in DataHub is designed to trace lineage across multiple platforms, datasets, pipelines, charts, and dashboards.
Once we launched Lineage, the next obvious step was to take things further to enable the visualization of end-to-end lineage for columns.
Why we built column-lineage
Column-level lineage is powerful in its potential to enable
- proactive impact analysis and
- reactive data debugging.
Here’s how. It not only lets you know if a dependency exists, but it also helps understand exactly how. This means that you can understand how a column is calculated so you can answer questions like:
- Which root input columns are used to construct this column?
- Does this column read from any sensitive data?
- What approach was used to come up with this aggregation?
It also means you can understand how a column is being used so you can answer questions like:
- Can I safely deprecate this field?
- Which dashboards are visualizing this column?
Regulatory compliance demands were another reason that made this feature a priority. Several DataHub users deal with sensitive data and need to have complete visibility into the columns with PII and how they link to destination tables in downstream dashboards.
Column-level lineage helps them connect the dots between columns with PII and user-facing dashboards so they can take precautions to ensure the sensitivity of this data.
Building column-level lineage in DataHub
Visualizing lineage metadata is undoubtedly a challenge. Show too little, and it fails to serve its purpose. Show too much, and it can become clunky and hard to visualize — and use.
Our key focus while building column-level lineage was ensuring that it was clean and easy to understand. The way to do this was to allow users to view as much or as little as they need.


DataHub Controls that let you view just what you need
The Column-Level Lineage Experience in DataHub
Here’s what you get with column-level lineage in DataHub:
- APIs for emitting column-level lineage
- Automatic column lineage extraction from Snowflake and Looker
- Column-level lineage visualization in the Lineage Explorer
- Impact Analysis of a single column
Using column-level lineage in DataHub
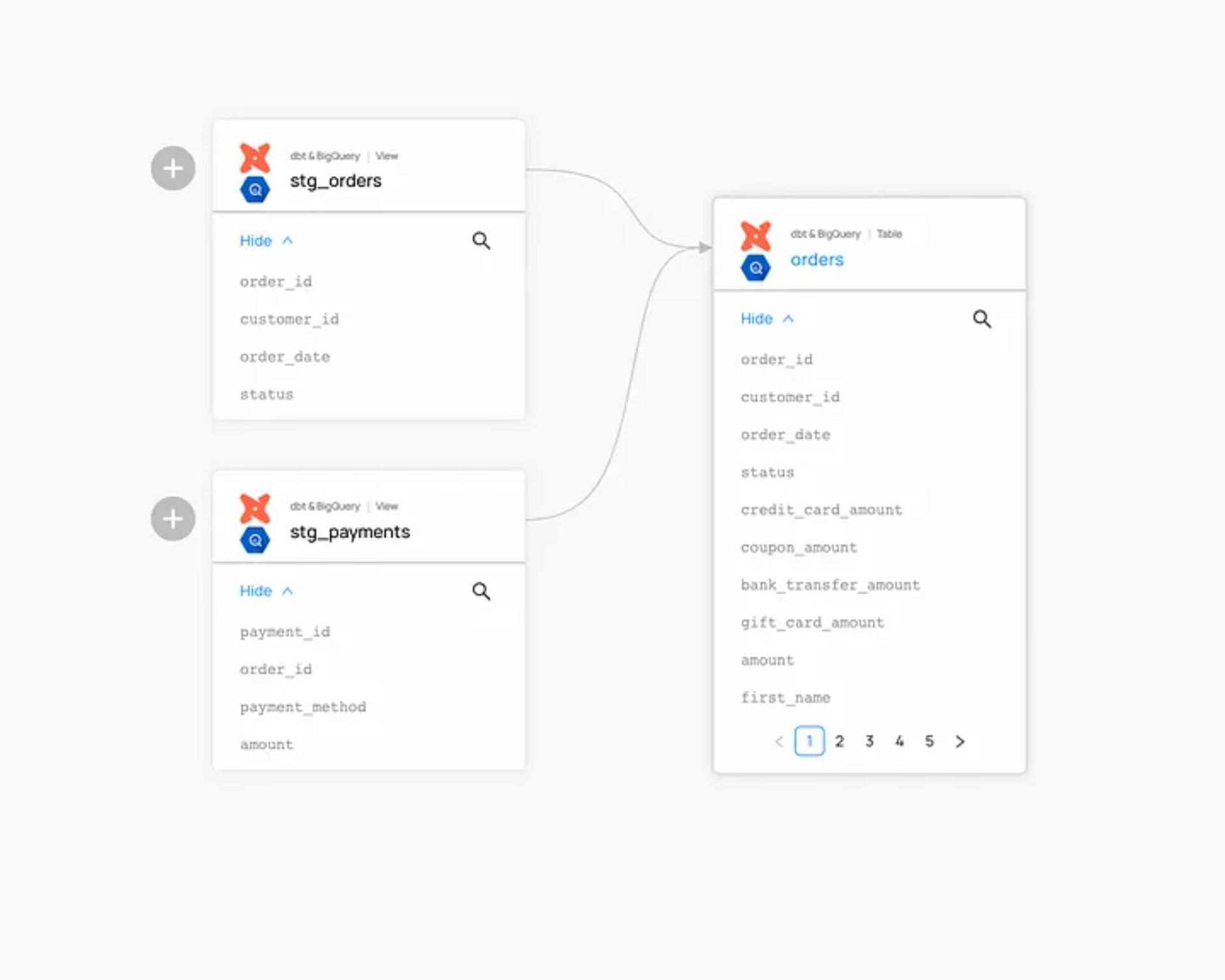
1. Viewing column-level lineage
Toggle the Show Columns control to switch between table-level and column-level lineage — in one click — without switching tabs, or losing context.
DataHub Controls that let you view just what you need
2. Impact Analysis at the column level
Just click on a table’s schema and select the column whose impact you want to analyze. Right-click the menu as shown below, to see its lineage.

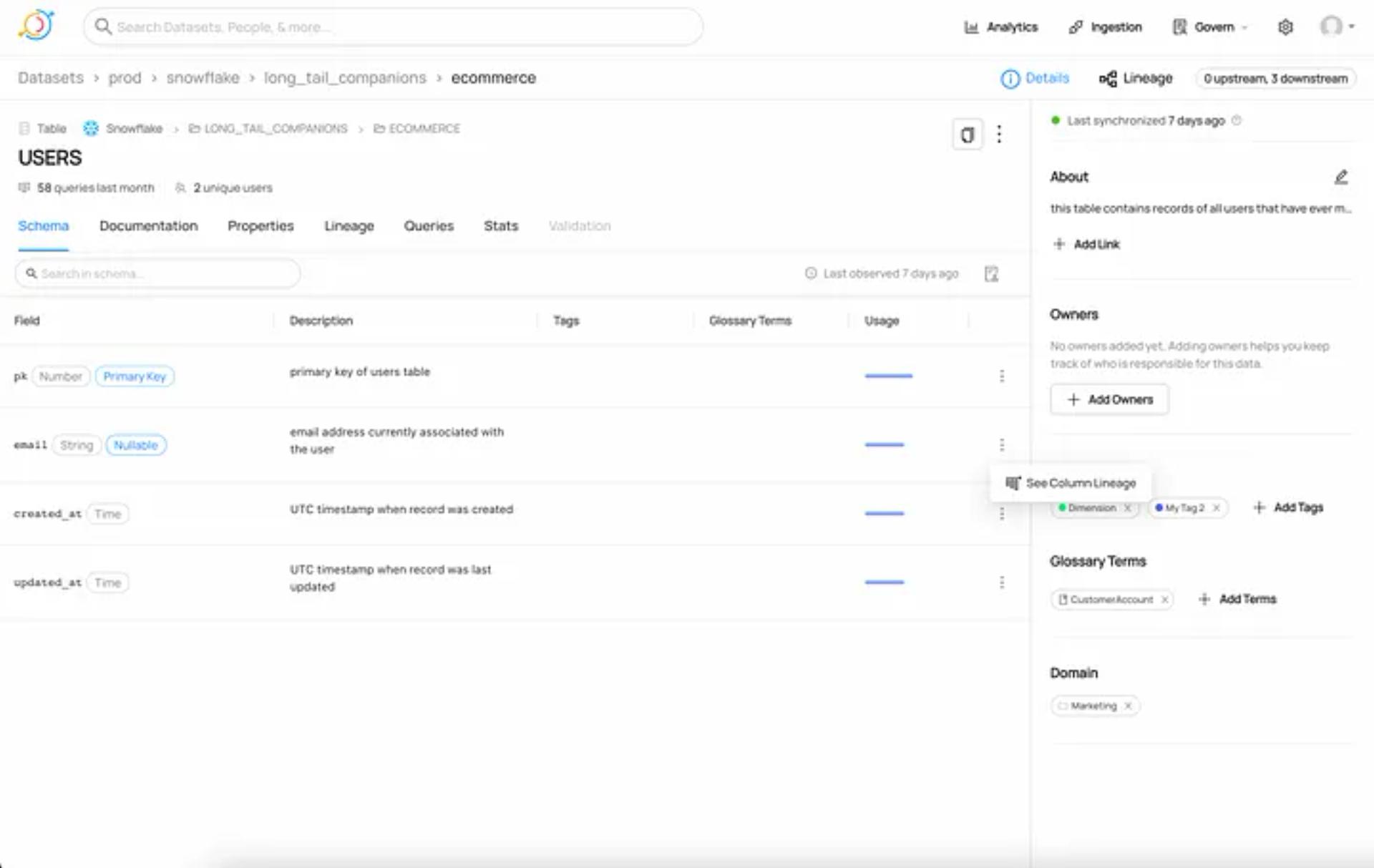
The Lineage Explorer shows you exactly what you need to know.
For instance, you can see the assets that directly consume the ‘email’ column by setting the degree of separation to 1, 2, or 3+ using the filter shown below.


To see further up/down, all you need to do is set your filters to higher/farther degrees of dependencies.

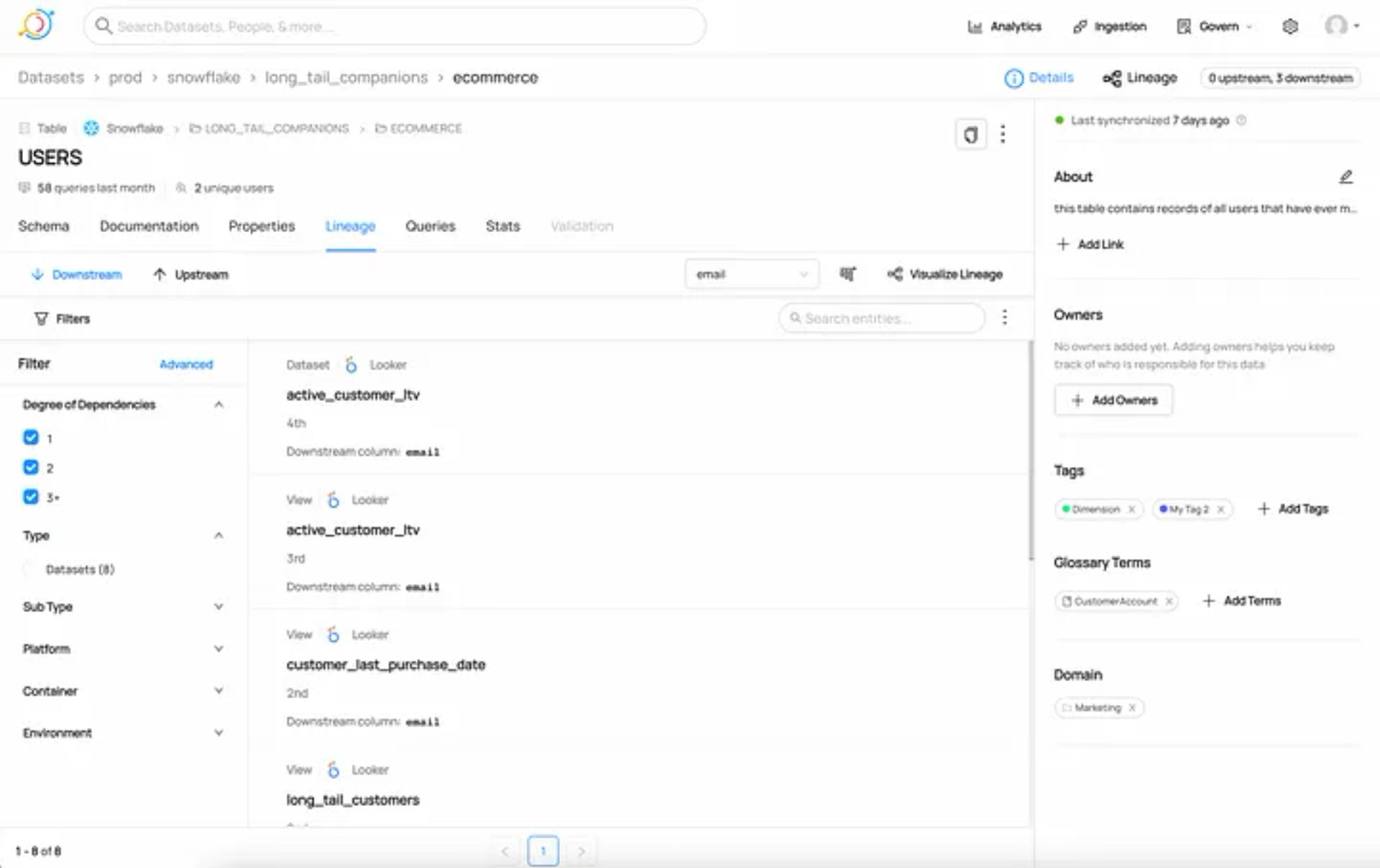
DataHub can also show you multiple paths corresponding to the different situations in which a column connects to another.

What’s next for column-level lineage?
- Viewing transformation logic used to derive a column
- Automatic column lineage extraction for other SQL sources starting with BigQuery and Redshift (Q4 2022)
- Support for Spark, Tableau (Q1 2023)
Want to see column-level lineage in action? Watch Chris Collins’s walkthrough from our September Town Hall here!
Connect with DataHub
Join us on Slack • Sign up for our Newsletter • Follow us on Twitter
Lineage
Data
DataHub
Data Lineage
Metadata

NEXT UP

Governing the Kafka Firehose
Kafka’s schema registry and data portal are great, but without a way to actually enforce schema standards across all your upstream apps and services, data breakages are still going to happen. Just as important, without insight into who or what depends on this data, you can’t contain the damage. And, as data teams know, Kafka data breakages almost always cascade far and wide downstream—wrecking not just data pipelines, and not just business-critical products and services, but also any reports, dashboards, or operational analytics that depend on upstream Kafka data.

When Data Quality Fires Break Out, You're Always First to Know with Acryl Observe
Acryl Observe is a complete observability solution offered by Acryl Cloud. It helps you detect data quality issues as soon as they happen so you can address them proactively, rather than waiting for them to impact your business’ operations and services. And it integrates seamlessly with all data warehouses—including Snowflake, BigQuery, Redshift, and Databricks. But Acryl Observe is more than just detection. When data breakages do inevitably occur, it gives you everything you need to assess impact, debug, and resolve them fast; notifying all the right people with real-time status updates along the way.


John Joyce
2024-04-23

Five Signs You Need a Unified Data Observability Solution
A data observability tool is like loss-prevention for your data ecosystem, equipping you with the tools you need to proactively identify and extinguish data quality fires before they can erupt into towering infernos. Damage control is key, because upstream failures almost always have cascading downstream effects—breaking KPIs, reports, and dashboards, along with the business products and services these support and enable. When data quality fires become routine, trust is eroded. Stakeholders no longer trust their reports, dashboards, and analytics, jeopardizing the data-driven culture you’ve worked so hard to nurture
John Joyce
2024-04-17