
DataHub 🤝 dbt Tests
Project Updates
Metadata
Open Source
Data Engineering
Community


Project Updates
Metadata
Open Source
Data Engineering
Community
👋 Hello, DataHub Enthusiasts!
I’m writing you from my sunny balcony, swinging in my hammock, and sipping on some lemonade. We Chicagoans take summer seriously; grab yourself a refreshing beverage and let’s get you caught up on what went down in the DataHub Community during June 2022.
The DataHub Community is growing faster than ever
I am constantly in awe of the vibrancy and helpfulness of the DataHub Slack Community. June 2022 was our highest growth month of all time; we welcomed over 375 new members to the DataHub Slack Community, surpassing 3,700 members (330% increase year-over-year). We continue to see between 800–900 weekly active users in Slack, posting well over 10k messages per month.


Want to get in on the action? Join us on Slack and RSVP to our next Town Hall!
More and more companies are deploying DataHub to production
🎉🎉 MASSIVE CONGRATS to the teams at N26 & Digital Turbine; both companies have officially adopted DataHub as their metadata management platform!
I love celebrating our open-source community members’ hard work and dedication, particularly when officially rolling out DataHub at a new organization. Hard work pays off!

Congrats to the N26 & Digital Turbine Teams!
Has your organization adopted DataHub? We’d love to celebrate you & your team at an upcoming Town Hall! Email us at community@datahubproject.io
DataHub 🤝 dbt— Integration Improvements
Surface dbt Test outcomes in DataHub
The Community asked, and we delivered: you can now surface the entire history of dbt Test outcomes on the Dataset entity page.


Surface outcomes of dbt Tests in a dataset entity page; see it in action here
Consolidated navigation of dbt resources
As of v0.8.39, dbt models and their associated warehouse tables are now merged into a unified entity within DataHub. This makes it much easier for end-users to navigate dbt and warehouse entities (i.e. Snowflake, BigQuery, etc.) in the lineage view and/or search experience:


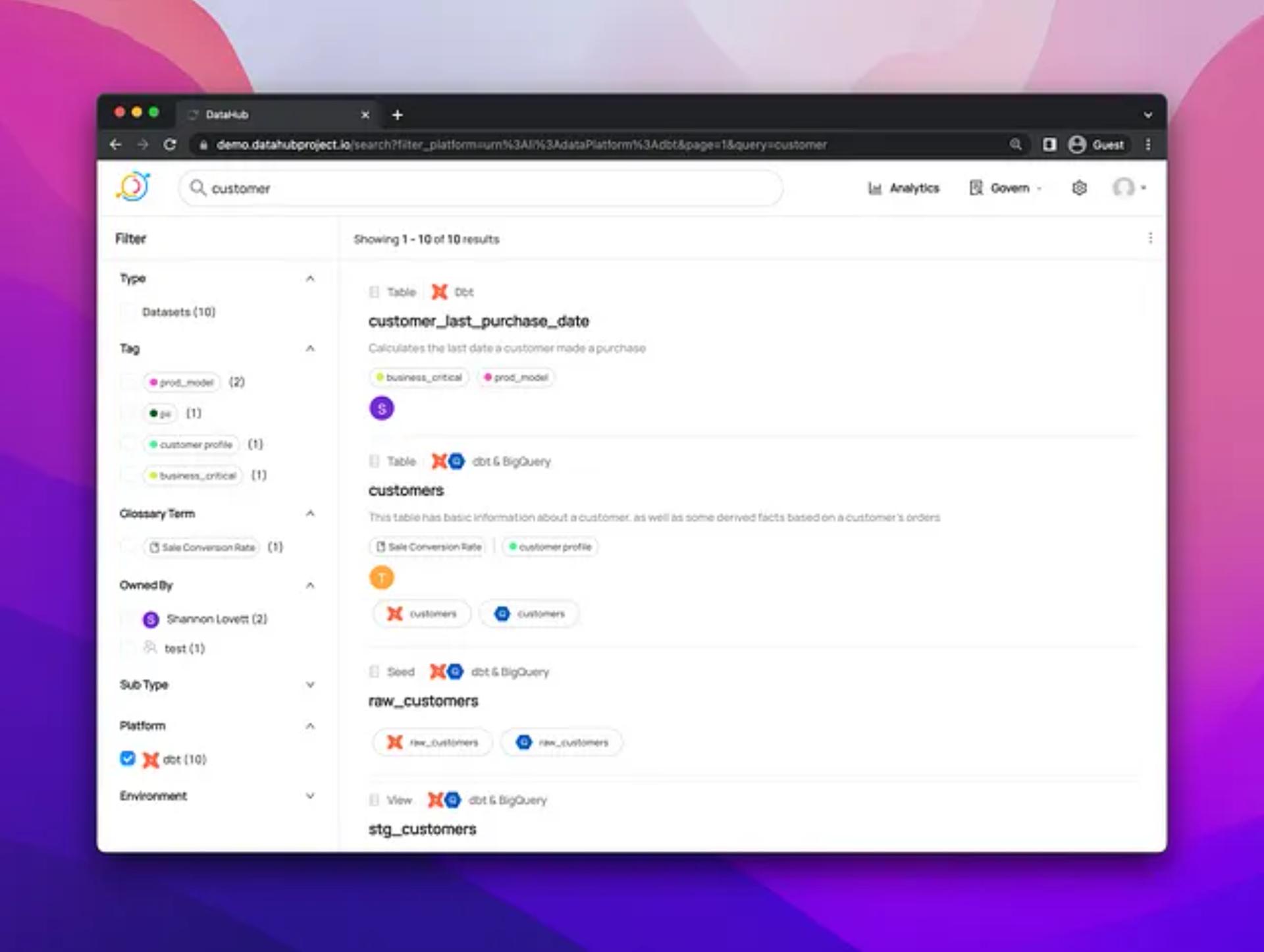
Quickly identify all upstream and downstream dependencies of a given entity
v0.8.39 introduces an improvement to our Lineage Impact Analysis. When looking at the Lineage tab, you can now quickly toggle between “Upstream” and “Downstream” entities to quickly understand the complete set of end-to-end dependencies:


Try out Impact Analysis here
New & Improved Metadata Ingestion Sources
We’re excited to announce that, as of v0.8.39, you can now make bulk edits to your DataHub entities via CSV. This will reduce the time and effort required to assign owners, Glossary Terms, and tags to entities within DataHub; read all about it here.
That’s not all! The highly-requested Spark Delta Lake ingestion source is LIVE as of v0.8.40! This has been one of the most-requested integrations in Q2'22; check out the docs and let us know what you think!
Last but certainly not least, we made improvements to our Snowflake and BigQuery ingestion sources: you can now configure data profiling only to run if the table has been updated within the prior N days. Set this configuration by using the profiling.profile_if_updated_since_days config in your Snowflake or BigQuery recipe.
Metadata Ingestion is getting easier and easier
We’re on a mission to make it easy for DataHub users to ingest metadata into DataHub.
We rolled out support for the new Java Kafka Emitter in v0.8.39 — use this when you want to decouple your metadata producer from the uptime of your DataHub metadata server by utilizing Kafka as a highly available message bus.
The next time you are configuring a new Metadata Ingestion Recipe, you can now use our ingestion recipe validator with your favorite code editor to flag configuration errors on the fly. Check out Tamas’s demo below.
Over 250 people have contributed to DataHub
Let that sink in for a minute… over two hundred fifty people have contributed code to the DataHub OSS Project 🤯 Pretty incredible, right?!
In June 2022, we merged 201 pull requests from 48 contributors, 14 of whom contributed for the first time (names in bold):
@aditya-radhakrishnan @afghori @alexey-kravtsov @Ankit-Keshari-Vituity @anshbansal @atulsaurav @BALyons @bda618 @BoyuanZhangDE @buggythepirate @cccs-eric @chen4119 @chriscollins3456 @claudio-benfatto @dexter-mh-lee @eburairu @endeesa @gabe-lyons @hsheth2 @jeffmerrick @Jiafi @jjoyce0510 @justinas-marozas @kangseonghyun @karoliskascenas @liyuhui666 @maggiehays @Masterchen09 @mayurinehate @MikeSchlosser16 @mmmeeedddsss @mohdsiddique @MugdhaHardikar-GSLab @nj7 @PatrickfBraz @pedro93 @piyushn-stripe @rslanka @RyanHolstien @Santhin @saxo-lalrishav @sayakmaity @sebkim @shirshanka @ShubhamThakre @skrydal @treff7es @xiphl
We are endlessly grateful for the members of this Community — we wouldn’t be here without you!
One Last Thing —
I caught up with my teammate, Aditya Radhakrishnan:
Maggie: Thinking back to what we shipped in June, what are you most excited for the Community to begin using?
Aditya: I love our newly-added support for visualizing dbt tests in DataHub! We’ve gotten a ton of feedback from the Community on how important dbt is to them, and I think this feature (along with visualizing merged dbt and warehouse entities) is a step in the right direction toward making dbt a first-class citizen in DataHub. We know how valuable of a tool it is for data practitioners, and I’m excited to continue to work with the Community in improving our integration with dbt. If you have feedback for us or other cool ideas on what we can do with dbt, please let us know!
M: Couldn’t agree more! Ok, unrelated — what song have you been playing on repeat this month?
A: It’s summer, so I’ve been playing more acoustic guitar recently and thinking a lot about where I’m at with my life, which has me really vibing with “Why Georgia” by John Mayer.
M: SO GOOD. John’s the man.
A: Lotta great John’s in the world (we have the best one tho — shoutout to John Joyce)
That’s it for this round; see ya on the Internet :)
Connect with DataHub
Join us on Slack • Sign up for our Newsletter • Follow us on Twitter
Project Updates
Metadata
Open Source
Data Engineering
Community

NEXT UP

Governing the Kafka Firehose
Kafka’s schema registry and data portal are great, but without a way to actually enforce schema standards across all your upstream apps and services, data breakages are still going to happen. Just as important, without insight into who or what depends on this data, you can’t contain the damage. And, as data teams know, Kafka data breakages almost always cascade far and wide downstream—wrecking not just data pipelines, and not just business-critical products and services, but also any reports, dashboards, or operational analytics that depend on upstream Kafka data.

When Data Quality Fires Break Out, You're Always First to Know with Acryl Observe
Acryl Observe is a complete observability solution offered by Acryl Cloud. It helps you detect data quality issues as soon as they happen so you can address them proactively, rather than waiting for them to impact your business’ operations and services. And it integrates seamlessly with all data warehouses—including Snowflake, BigQuery, Redshift, and Databricks. But Acryl Observe is more than just detection. When data breakages do inevitably occur, it gives you everything you need to assess impact, debug, and resolve them fast; notifying all the right people with real-time status updates along the way.


John Joyce
2024-04-23

Five Signs You Need a Unified Data Observability Solution
A data observability tool is like loss-prevention for your data ecosystem, equipping you with the tools you need to proactively identify and extinguish data quality fires before they can erupt into towering infernos. Damage control is key, because upstream failures almost always have cascading downstream effects—breaking KPIs, reports, and dashboards, along with the business products and services these support and enable. When data quality fires become routine, trust is eroded. Stakeholders no longer trust their reports, dashboards, and analytics, jeopardizing the data-driven culture you’ve worked so hard to nurture
John Joyce
2024-04-17