
Detecting Deep Data Quality Issues with Column-Level Assertions
Data Engineering
Metadata Management
Data Governance
Data Quality


Data Engineering
Metadata Management
Data Governance
Data Quality
Picture this
You're a data engineer at a boutique e-commerce start-up. Your company sells luxury goods at steep discounts. One of your many responsibilities involves monitoring the flash_sale_purchase_events table in your start-up’s Snowflake data warehouse. Updates to columns in this table are supposed to reflect real-time participation by customers in the limited-time flash sales your company offers.
It’s mid-December. Just a couple weeks before Christmas. Your company kicks off a series of flash-sales showcasing a few select luxury apparel brands.
Demand is through the roof. Your data platform layer can't keep up with the firehose of events being ETL’d onto your warehouse from Apache Kafka. In an attempt to reduce load, you task a junior data engineer with adding an intermediate filtering step just before your transformation layer using a new Airflow task.
Unfortunately, the engineer accidentally deploys two duplicate versions of the new task to production, causing the same records to be sent to the flash_sale_purchase_events table twice. This goes unnoticed by your team for an entire week.
Meanwhile, your company’s marketing team has been closely monitoring the purchasing metrics. Eager to capitalize on what they believe to be stellar engagement, they pour gas on the flame and increase budget across their portfolio of social ad campaigns. Unfortunately for them, the return on ad spend will turn out to be far lower than they’ve been led to believe.
Could you have done anything to avoid this Nightmare-Before-Christmas scenario? Of course! You could have proactively caught the duplication issue before it caused widespread impact using column-level data quality checks for your table.
Introducing Column-Level Assertions
With Acryl Cloud, you can use the Column Assertions feature to monitor changes to critical warehouse tables at the column level and validate them against user-defined criteria.
What happens when something goes wrong? Acryl’s Subscriptions and Notifications feature allows you to create alerts that trigger when quality issues are detected. This ensures that data and governance leaders, data producers, and downstream consumers (like, cough, the marketing team) are in the loop, too.
Here are a few common issues Column Assertions can help detect:
- Duplicate Data. In the real world, data duplication is a common problem, thanks to the complexity involved in designing idempotent logic for data pipelines. It’s also a concern in BASE databases, like Cassandra or DynamoDB, where relaxed consistency safeguards make it difficult to enforce consistency. This is true, too, of optimized file formats like Parquet, Iceberg, and even Delta Lake, where poorly designed data pipelines can duplicate or lose data.
- Missing Data. This happens when fields that should be populated in a dataset are missing. In an RDBMS, this sometimes happens when columns are left blank during an INSERT operation. By default, blank fields are represented as NULL, unless constrained otherwise. The presence of NULLs where data is expected indicates a data quality issue. Conversely, the presence of non-NULL values in columns that should have NULLs is also a data quality problem. Column Assertions allow you to detect both issues.
- Invalid data values or types. This occurs when new records or updates to a column fall outside of predefined ranges or contain unexpected values or types. Your Oracle DBA might say, “Just enforce column-level constraints in the database!” but not all databases enforce the same constraints, while some databases, like Snowflake, don’t actually enforce any meaningful constraints. BASE databases don’t enforce constraints, and Parquet and Iceberg don’t, either.
- Anomalous Data Patterns. Unusual spikes in data volume or in record counts, as with the replication of records at a rate significantly higher than expected in a given period of time, can be indicative of pipeline misconfigurations, software bugs, or other problems.
By taking advantage of the Column Assertions feature in Acryl Cloud, organizations can identify data issues before they cause a major incident. Column Assertions feature adds to the suite of data quality checks already provided by Acryl Cloud: Freshness Assertions and Volume Assertions.
Column Assertions Explained
Before we return to our harried data engineer and the malfunctioning data pipeline that ruined Christmas, let’s tackle a more basic question: What are Column Assertions, and how do they work?
A simple explanation is that they’re column-level validation rules, similar to database (1)constraints—albeit much easier to implement, manage, and share with your team.
In other words, a Column Assertion is literally an “assertion” you make about the uniqueness, nullability, type, value, range, etc. of the data in a column.
This assertion is backed up by two types of checks:
- Column Metric Assertions: validate that a metric obtained by aggregating over a given column’s values matches your expectations (e.g. MIN, MAX, MEAN, MEDIAN).
and
- Column Value Assertions: validate that each row has a semantically “valid” column value

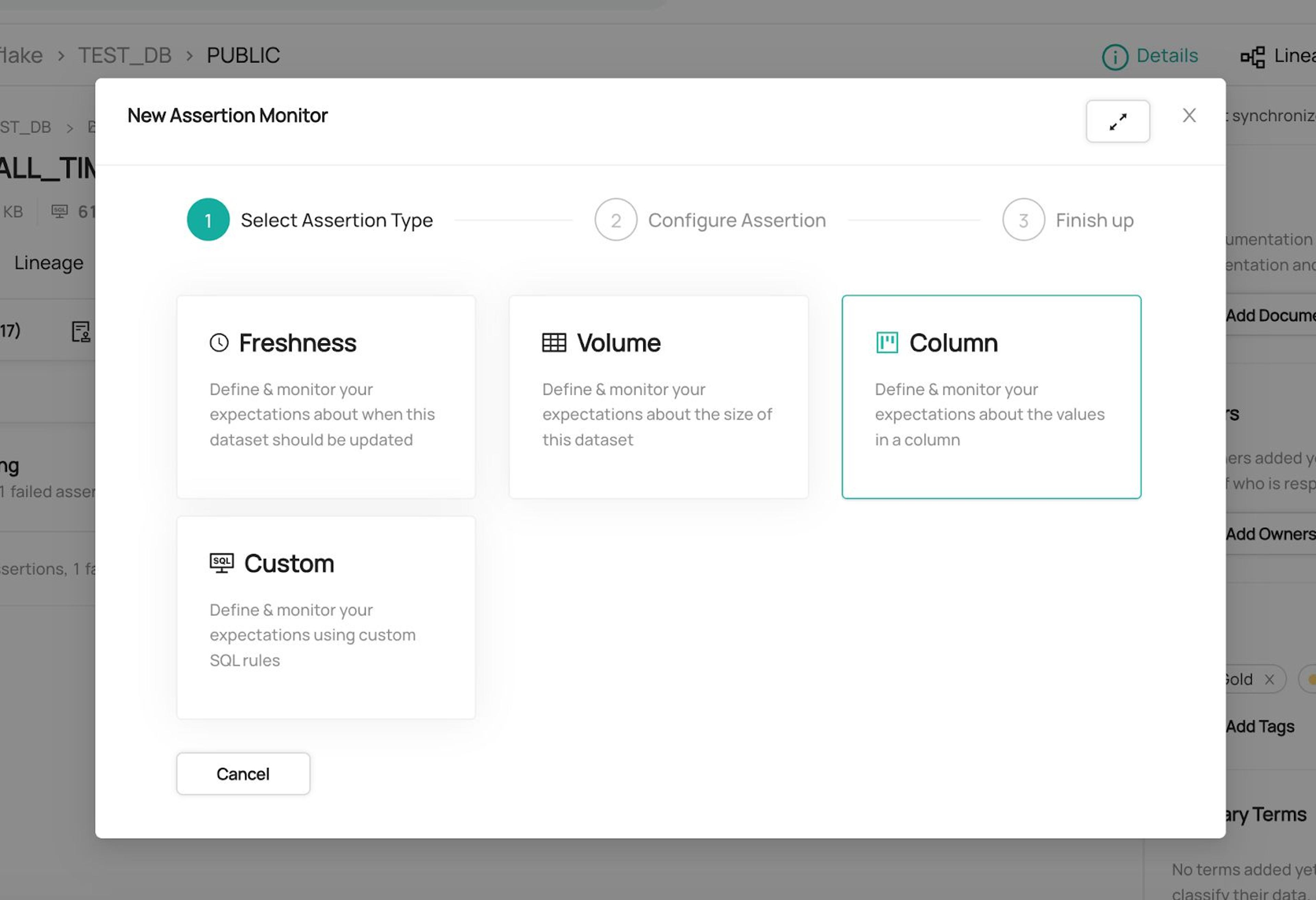
In Acryl Cloud, these checks are carried out by running tailored queries against specific columns of a database table, for either the entire table or just the parts that have recently changed. In the event that a column check fails, a notification will be sent to subscribers of that data asset.
To configure a Column Assertion, you'll need to (a) specify how often your checks will occur and (b) define the assertion criteria (i.e., conditions) used to validate the column data.
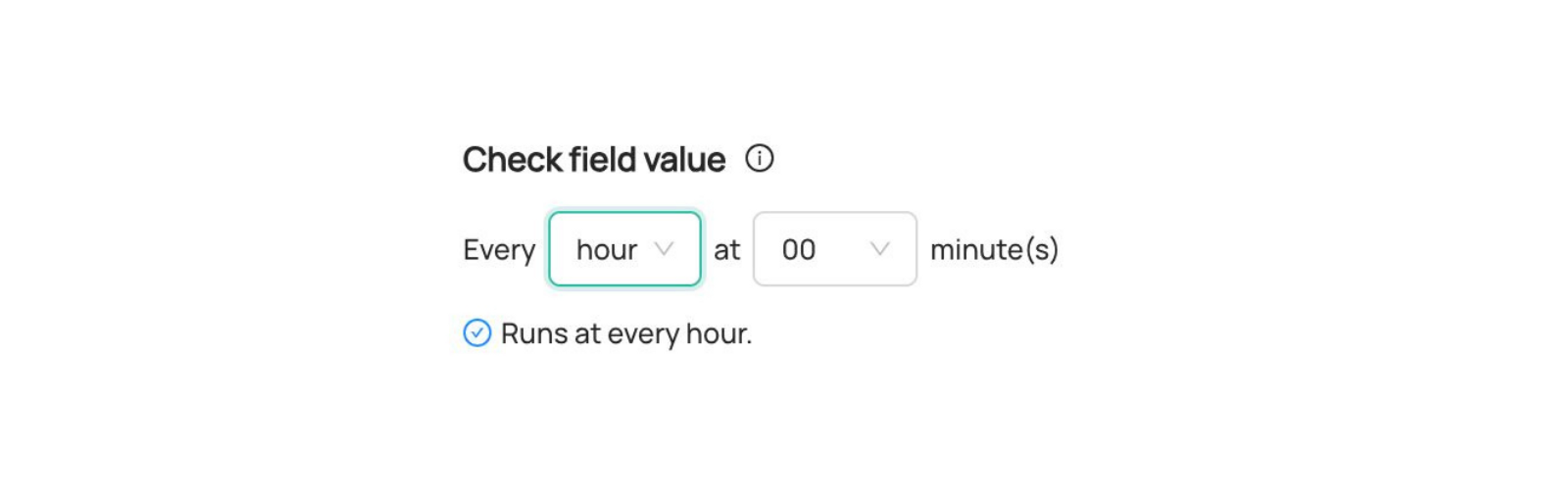
1. Evaluation Schedule
This defines how often Acryl Cloud will run your checks against a given warehouse column. For time-sensitive applications, it’s a good idea to align this with the expected change frequency of the column.
You can configure checks to run n times per hour, on an hourly basis, daily, weekly, etc.

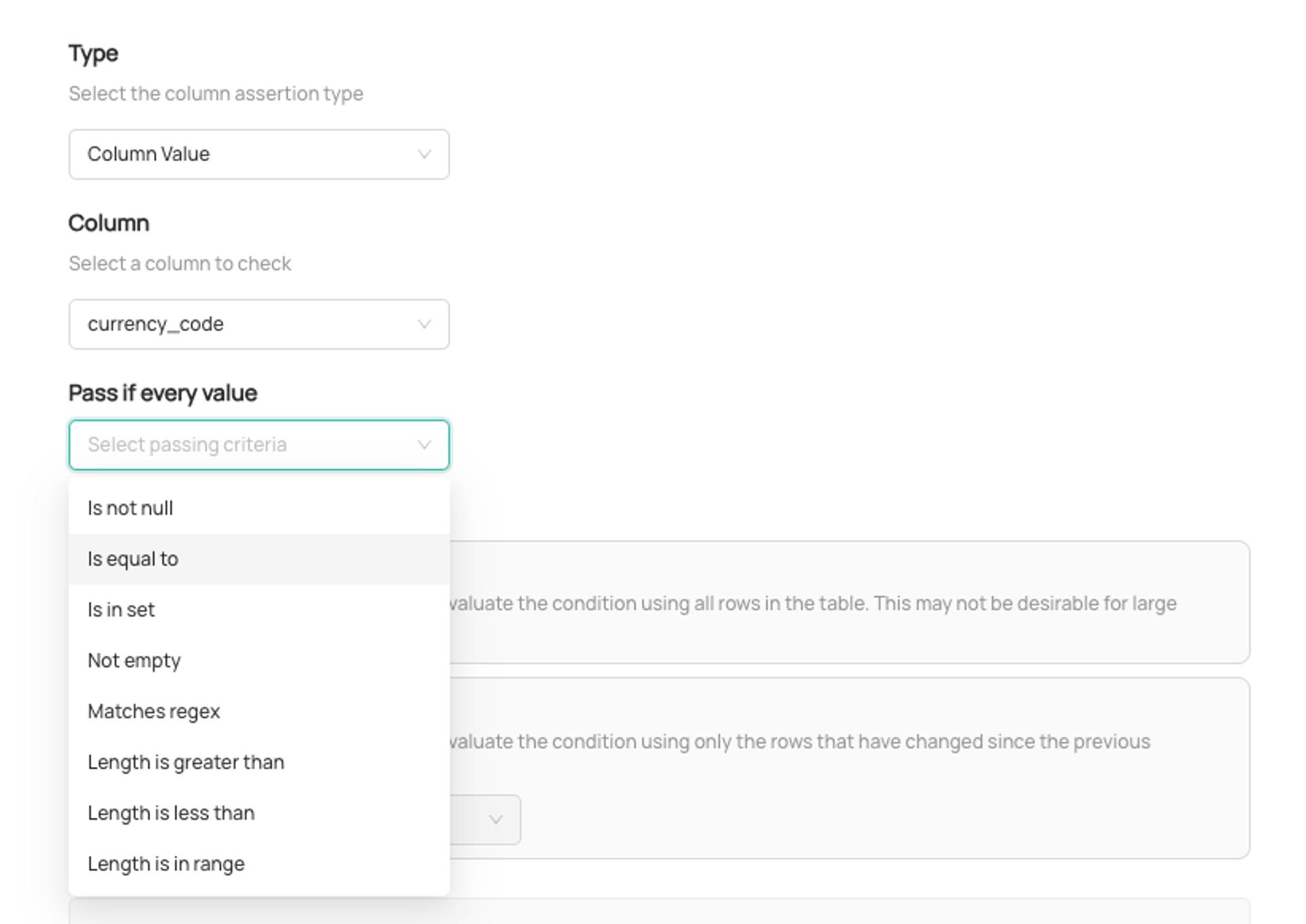
2. Column Condition
This is where you define the criteria for your check. In other words, the scenario in which determines whether the assertion should fail.

You can create assertions that validate a column using the following aggregate metrics:
- Null Count: The number of rows where a given column is null. For example, to alert if a
credit_card_numbercolumn is ever empty - Unique Count: The number of rows having a unique value for a given column. For example, to check that
order_idhas a unique count equal to the total count of orders - Maximum: The maximum value for a numeric column. For example, to check that
order_amountdoes not go below a maximum threshold - Minimum: The minimum value for a numeric column. For example, to ensure that an
inventory_countnever falls below 1 - Mean: The average value for a numeric column. For example, to alert if
average_customer_ratingdrops below a certain mean value; - Median: The median value for a numeric column. For example, to alert if
time_on_sitevalues drop. - Standard deviation: The standard deviation of a numeric column. For example, to check
daily_salesfor unusual variations; useful for pinpointing anomalies or outliers - Max + min length (Strings): The maximum or minimum length for a string column. For example, to validate that
postal_codecontains the expected number of characters;
and those which validate individual values for a given column using the following operators:
- Expected Values Set: Verify that each value for a column matches one of a set of expected values. For example, to check that
status_codeis within a predefined set of values - Regex Match: Verify that all values for a given column match a specific regex pattern. For example to ensure that
customer_idmatches a specific regex pattern - Range Check: Verify that all values for a given column fall into a specific numeric range. For example, to alert if
discount_percentageis not within the expected range of 0-50% - Nullability: Verify that all values for a column are not null
For column value validation assertions, you can also configure an invalid values threshold or the number of rows that must validate your column value condition before triggering a failure of the assertion.


You can use Column Assertions to proactively detect and take action against a wide variety of data quality issues—from operational incidents to outright fraud.
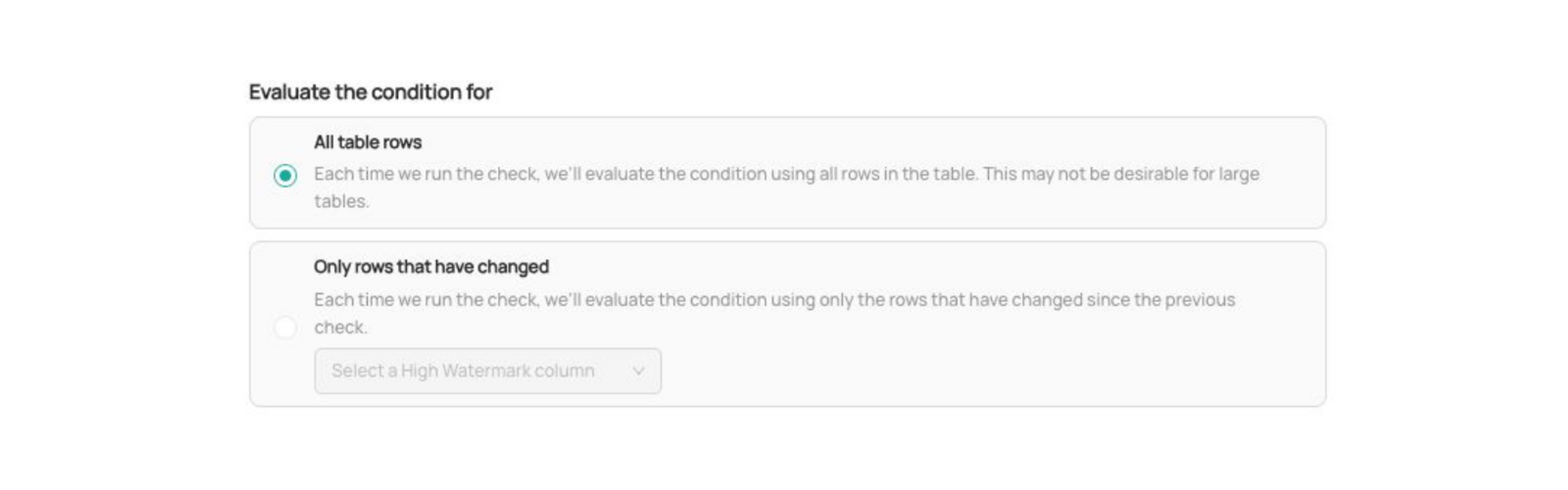
3. Rows to Evaluate
Finally, you can choose which rows should be considered when evaluating the column condition defined in step 2. Both column metric and column value assertions can be run across
- all the rows in the table OR
- only rows which have changed since the previous assertion run
which makes it easy to create efficient checks that also validate all data in your table incrementally – as it gets added to the table.
You can create assertions that validate a column using the following aggregate metrics:
- Null Count: The number of rows where a given column is null. For example, to alert if a
credit_card_numbercolumn is ever empty - Unique Count: The number of rows having a unique value for a given column. For example, to check that
order_idhas a unique count equal to the total count of orders - Maximum: The maximum value for a numeric column. For example, to check that
order_amountdoes not go below a maximum threshold - Minimum: The minimum value for a numeric column. For example, to ensure that an
inventory_countnever falls below 1 - Mean: The average value for a numeric column. For example, to alert if
average_customer_ratingdrops below a certain mean value; - Median: The median value for a numeric column. For example, to alert if
time_on_sitevalues drop. - Standard deviation: The standard deviation of a numeric column. For example, to check
daily_salesfor unusual variations; useful for pinpointing anomalies or outliers - Max + min length (Strings): The maximum or minimum length for a string column. For example, to validate that
postal_codecontains the expected number of characters;
and those which validate individual values for a given column using the following operators:
- Expected Values Set: Verify that each value for a column matches one of a set of expected values. For example, to check that
status_codeis within a predefined set of values - Regex Match: Verify that all values for a given column match a specific regex pattern. For example to ensure that
customer_idmatches a specific regex pattern - Range Check: Verify that all values for a given column fall into a specific numeric range. For example, to alert if
discount_percentageis not within the expected range of 0-50% - Nullability: Verify that all values for a column are not null
For column value validation assertions, you can also configure a invalid values threshold or the number of rows which must validate your column value condition before triggering a failure of the assertion.
Let’s jump back to our data engineer, trapped in their E-Commerce Nightmare Before Christmas.
How could Column Assertions have helped them?
In several ways suppose the flash_sale_purchase_events table has roughly a dozen columns, including a few particularly important ones: sale_event_id, user_id, session_id, event_timestamp, transaction_amount
The easiest fix—and a common-sense measure, if you’re an e-commerce vendor!—is to enforce uniqueness assertions on the user_id and sale_event_id columns.
This would quickly surface the duplicate records problems. In fact, with Acryl Cloud’s Subscriptions and Notifications feature, not just the data engineer, but also any relevant stakeholders—like the growth marketing manager—would have been alerted to the anomaly as soon as it was detected.
Takeaways
In e-commerce and beyond, Column Assertions allow you to proactively detect and remedy not just edge or corner-case “issues,” but the types of everyday problems you're going to encounter in the real-world.
Observing changes at the column-level is an essential part of proactive, pragmatic data governance, allowing you to detect and correct pipeline anomalies, system issues, user errors, and malicious activity before Christmas is ruined.
The primary advantage of Column Assertions over other types of checks is that you’re able to look deeper—beyond surface-level table metrics into the actual contents of the data, allowing for the detection of more nuanced issues like partially missing or duplicated data.
Column Assertions complement existing features including Freshness, Volume, and Custom SQL Assertions and a key part achieving the broader vision for the Acryl product: to be the single source-of-truth for both the technical and non-technical (governance & compliance) health for every data asset inside an organization.
(1)Constraints are typically enforced by an RDBMS engine; formats like Parquet and Iceberg lack a built-in means to enforce them. If you’re brave enough, however, you could design the transactional logic to do this yourself.
Questions? Feedback? Join us in DataHub Slack and tell us all about it!
Book a demo to see all the other cool stuff we’re building for Acryl DataHub!
Data Engineering
Metadata Management
Data Governance
Data Quality

NEXT UP

Governing the Kafka Firehose
Kafka’s schema registry and data portal are great, but without a way to actually enforce schema standards across all your upstream apps and services, data breakages are still going to happen. Just as important, without insight into who or what depends on this data, you can’t contain the damage. And, as data teams know, Kafka data breakages almost always cascade far and wide downstream—wrecking not just data pipelines, and not just business-critical products and services, but also any reports, dashboards, or operational analytics that depend on upstream Kafka data.

When Data Quality Fires Break Out, You're Always First to Know with Acryl Observe
Acryl Observe is a complete observability solution offered by Acryl Cloud. It helps you detect data quality issues as soon as they happen so you can address them proactively, rather than waiting for them to impact your business’ operations and services. And it integrates seamlessly with all data warehouses—including Snowflake, BigQuery, Redshift, and Databricks. But Acryl Observe is more than just detection. When data breakages do inevitably occur, it gives you everything you need to assess impact, debug, and resolve them fast; notifying all the right people with real-time status updates along the way.
John Joyce
2024-04-23

Five Signs You Need a Unified Data Observability Solution
A data observability tool is like loss-prevention for your data ecosystem, equipping you with the tools you need to proactively identify and extinguish data quality fires before they can erupt into towering infernos. Damage control is key, because upstream failures almost always have cascading downstream effects—breaking KPIs, reports, and dashboards, along with the business products and services these support and enable. When data quality fires become routine, trust is eroded. Stakeholders no longer trust their reports, dashboards, and analytics, jeopardizing the data-driven culture you’ve worked so hard to nurture
John Joyce
2024-04-17