
LinkedIn DataHub Project Updates
Data Engineering
Open Source
Metadata
Dbt
Project Updates


Data Engineering
Open Source
Metadata
Dbt
Project Updates
Introduction
This is the third post covering monthly project updates for the open-source metadata platform, LinkedIn DataHub . This post captures the developments for the month of April in 2021. To read the March 2021 edition, go here . To learn about Datahub’s latest developments- read on!
Community Update
First an update on the industry landscape! On May 19th, we’re co-hosting Metadata Day 2021 with LinkedIn and Acryl Data. This time, our focus is on Data Mesh , an emerging topic of high interest in the data community. Please sign up for the public meetup at our event page .


Metadata Day 2021 Spring Edition
Project Update
We kept up our monthly commit activity rate of 130 commits/month and our latest release (0.7.1) includes 21 unique contributors from 12 different companies! In the 5 weeks from March 19 to April 30, we had 171 PRs that were merged in and our Slack community grew by 25%. We had more than 80 people attending the monthly town-hall , where community members showcased their recent contributions and talked through their adoption journeys. Join us on Slack and subscribe to our YouTube channel to keep up to date with this fast growing project.
The big updates in the last month were in three tracks:
Product Improvements
- Delightful lineage visualization to help you explore the flow of your data across your ecosystem.
- Pipelines and Tasks (a.k.a. Workflows or DAGs) are now searchable and browsable.
- Search improvements: now matches query on column names.
- The landing page provides helpful search suggestions to get you started.
- Editable column level descriptions to make sure your documentation stays up to date.
- Support for nested schema visualization.
Operator Tools
- The datahub CLI is now generally-available as a python package (pip install acryl-datahub) and has evolved beyond ingest to also support the check verb that lets you validate that your local docker deployment is ship-shape.
- Production-ready helm charts for deploying DataHub in your environment are now officially supported! Check them out here .
New Integrations
- Rich integration with Airflow that emits DAGs, tasks and lineage to Datahub. This integration supports lineage via the Airflow Lineage API or the DatahubEmitterOperator .
- Support for integration with many other systems!


Datahub Integrations
- An official release 0.7.1 that packages all these improvements
Read on to find out more!
Airflow Lineage Integration
Airflow is widely used as an orchestrator for ETL pipelines, which means it produces a rich sequence of tasks and datasets, all of which are interrelated. While you could always keep your schemas and metadata fresh by scheduling DataHub ingestion recipes, you can now capture the metadata and lineage of your Airflow DAGs themselves.
The best way to do this is by using the DataHub lineage backend. You simply set a couple of configuration options and declare the datasets each task produces and consumes. Once the DAG runs, you’ll start to see your DAGs under “pipelines” in the DataHub UI, and individual tasks will appear in the lineage views, including all the connections between each task and the datasets it produces and consumes. For both DAGs and tasks, you’ll also see rich metadata, including descriptions, start dates, file locations, and the raw task parameters.
The lineage backend works in Airflow 2.0.2+ or 1.10.15+. With older versions of Airflow, you can achieve a subset of this functionality using the DatahubEmitterOperator . That operator is not limited to lineage, and can be used to emit any metadata to DataHub.
With the DataHub-Airflow integration, you can now understand how your ETL pipelines connect with the rest of your data ecosystem.
dbt Integration
dbt is a tool used to define and execute templated SQL queries. Although Dbt provides a lineage visualization itself, this view only shows relationships between dbt entities. There is no way to see what dependencies the outside world may have on dbt.
Thanks to contributions by Gary Lucas , Datahub solves this problem now. The new dbt integration collects model, source, lineage and schema information. Other integrations (such as Airflow or Superset) can add relationships between your dbt datasets and charts, pipelines, or external datasets. Now, you can have a complete picture of how dbt connects to the rest of your data ecosystem, all in one place.
Lineage in Action with Airflow and Superset
Datahub receives lineage from sources like Superset, dbt and Airflow. After emitting, Datahub users can now explore lineage in the Datahub UI. This allows data workers to understand how data flows from datasets, through ETL tasks, up to the charts and dashboards that consume them.
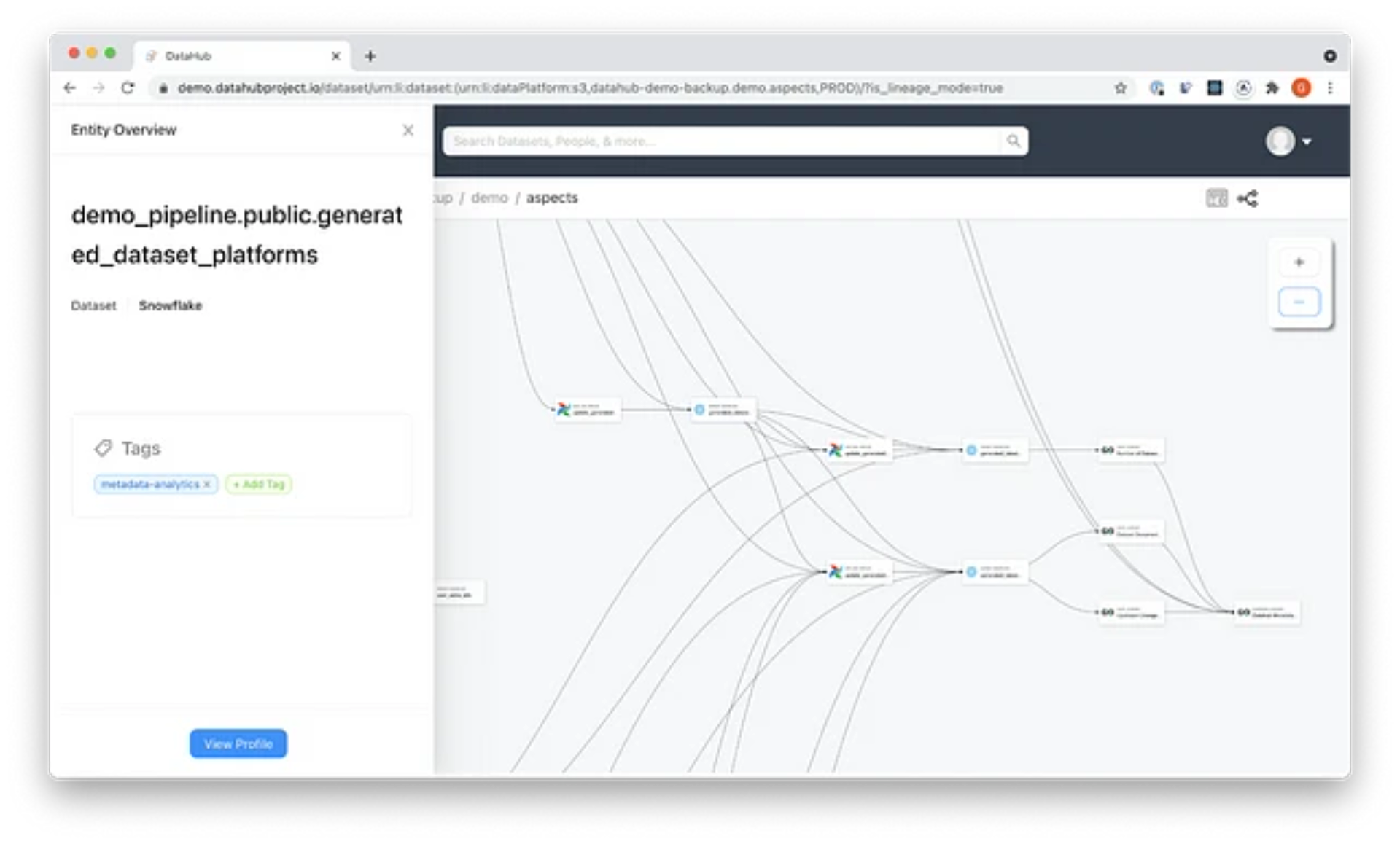
Datahub Demo
To test if Datahub’s lineage feature captures and displays lineage information effectively, we created our own metadata analytics pipeline and integrated it with DataHub. The pipeline analyzes metadata of the test datasets we have loaded into demo.datahubproject.io .
You can explore the pipeline more on the DataHub demo site. A good place to start is the snapshot of our demo database loaded into s3 . From there, we create an s3 document per aspect and load those into Snowflake. Our airflow pipeline does further transformations once the data lands in Snowflake to make it easier to work with. Finally, the data is consumed by a few charts in a Superset dashboard.
Using Datahub we can get a picture of our entire metadata pipeline- from the first snapshot that lands in s3 all the way to the Superset charts that consume them.
Watch the demo that shows how to explore and discover this pipeline below:
Case Study: DataHub at DefinedCrowd
Pedro Silva walked us through how he used Datahub to democratize data at DefinedCrowd.
The central data team was finding themselves overwhelmed with operational load. Data workers needed constant support to answer data questions. The central data team was so busy connecting people with the data they were looking for, they had no time to work on improvements to the core infrastructure. DefinedCrowd needed a data catalog.
They surveyed many possible solutions, but landed on Datahub for a few key reasons:
- The active community. Pedro got support he needed quickly and was easily able to contribute back. (Want to see for yourself? Join our slack and say hi!)
- A strongly typed dynamic metadata model. Pedro needed to be able to customize his metadata model. He liked the flexibility and type safety that Datahub provides.
- A push/pull ingestion model. DefinedData had streaming and batch cases where they wanted to emit metadata. They needed a data catalog that could support both.
So far, they have indexed their downstream datasets and are running Datahub in production. The Central Data Team is able to offload their operational work and users reported to have a “very positive experience” with the catalog. Success!
Pedro and team also contributed back Druid support and added JMX exporters to all DataHub java containers so that metrics can be exposed and consumed by logging services like Prometheus. Thank you Pedro!
You can watch the video of Pedro’s presentation here:
Case Study: DataHub at Depop
We heard from John Cragg at Depop who just completed a hackathon comparing Amundsen and Datahub. In the end, Depop chose Datahub and John walked us through their process.
Before adopting Datahub, there was no centralized place to find Depop’s metadata. To find a dataset, understand lineage information or learn the meaning of a field, data workers relied on Slack channels to track down the right person. This situation was not scalable, and made it nearly impossible for new employees to get ramped up. Enter- the data catalog hackathon!
Depop compared Amundsen and Datahub across a few key dimensions. In the end, Datahub’s native support for streaming ingestion, our community and our rich lineage support were the deciding factors. Now, their data workers have a single source of truth to answer all of their metadata questions.
The full video of their presentation is here:
We are excited to have Depop join the community. During their hackathon, they partnered with folks at Klarna to contribute back Glue support- thank you! I look forward to more contributions to come.
Looking Forward
The pace of innovation and development continues to accelerate.
We’re starting to get into the meat of our Q2 roadmap , working on Usage Analytics and no-code metadata modeling with the community. Meanwhile integrations with systems like Looker, Hive and Glue are continuing to get better and deeper! Next on deck, we’ll be adding Role-Based Access Control and support for Business Glossary. Until next time!
Data Engineering
Open Source
Metadata
Dbt
Project Updates

NEXT UP

Governing the Kafka Firehose
Kafka’s schema registry and data portal are great, but without a way to actually enforce schema standards across all your upstream apps and services, data breakages are still going to happen. Just as important, without insight into who or what depends on this data, you can’t contain the damage. And, as data teams know, Kafka data breakages almost always cascade far and wide downstream—wrecking not just data pipelines, and not just business-critical products and services, but also any reports, dashboards, or operational analytics that depend on upstream Kafka data.

When Data Quality Fires Break Out, You're Always First to Know with Acryl Observe
Acryl Observe is a complete observability solution offered by Acryl Cloud. It helps you detect data quality issues as soon as they happen so you can address them proactively, rather than waiting for them to impact your business’ operations and services. And it integrates seamlessly with all data warehouses—including Snowflake, BigQuery, Redshift, and Databricks. But Acryl Observe is more than just detection. When data breakages do inevitably occur, it gives you everything you need to assess impact, debug, and resolve them fast; notifying all the right people with real-time status updates along the way.


John Joyce
2024-04-23

Five Signs You Need a Unified Data Observability Solution
A data observability tool is like loss-prevention for your data ecosystem, equipping you with the tools you need to proactively identify and extinguish data quality fires before they can erupt into towering infernos. Damage control is key, because upstream failures almost always have cascading downstream effects—breaking KPIs, reports, and dashboards, along with the business products and services these support and enable. When data quality fires become routine, trust is eroded. Stakeholders no longer trust their reports, dashboards, and analytics, jeopardizing the data-driven culture you’ve worked so hard to nurture
John Joyce
2024-04-17