
The Stripe Story: Beating data pipeline observability and timeliness concerns with DataHub
Stripe
DataHub
Community
Open Source
Data Engineering


Stripe
DataHub
Community
Open Source
Data Engineering
This post, part of our DataHub Blog Community Contributor Program, is written by Divya Manohar, DataHub Community member and Data Platform Engineer at Stripe
About Stripe and the Stripe Data Platform team
Stripe is a payment services provider that enables merchants to accept credit and debit card payments. Our products power payments for online and in-person retailers, subscription businesses, software platforms, and marketplaces. Stripe also helps companies beat fraud, send invoices, get financing, manage business spend, and more.
The Data Platform team at Stripe operates and supports the infrastructure for complex batch data pipelines, besides closely monitoring their landing times and additional performance metrics every day.
Our Challenge
At the Stripe Platform team, one of our biggest struggles has been with data observability and timeliness for the complex data pipelines that we operate and support.
For instance, one of our most important data pipelines, the Unified Activity Report (UAR) generates a summary of Stripe users’ transactions at the end of each month. It consists of nearly 1000 Data Jobs with very complex dependencies and has a strict 72-hour deadline for completion.
Data Job owners ended up spending a lot of time and effort
- manually monitoring the UAR (click through hundreds of job status pages to understand how their jobs have been performing over time),
or - building custom pipeline-specific dashboards for detailed observability of their job performances
We use Airflow for scheduling and running batch Data Jobs (or tasks) that run into thousands every hour. To make a connection between the datasets that are produced and the Data Jobs producing them, teams were often required to search through runtime logs to determine what input and output data sets are being consumed and produced.
The Airflow UI doesn’t offer much in terms of flexibility in creating dashboards to showcase insights into historical DAG trends and job performances, as well as showcasing cross-DAG dependencies.
This posed a huge visibility problem that led to a timeliness problem, and ended up being a source of stress and worry for Data Job owners — since they had strict SLAs (service level agreements) regarding landing time, latency, and freshness of their data.
Solution Approach
We wanted to…
- Empower our data pipeline-owning teams to quickly and easily determine the status of an entire pipeline via a dashboard that they could use to track the progress of the pipeline.
- Give users a self-serve approach to build customized historical SLA-tracking dashboards so they had the flexibility to monitor and track their critical Data Job.
For this, we needed a unified data catalog that teams could use to get quick, easy insights into their jobs, runtimes, latency, and SLA misses, as well as their pipelines’ status and estimated delivery times.
It’s this need for discoverability, visibility, and flexibility that brought us to DataHub.
Why DataHub
As a DataHub community member, I knew how it was focused on enabling discovery and observability for complex data ecosystems. What this translated into, for us, was complete discoverability for jobs and datasets. Whether it was documentation, schemas, ownership, lineage, pipelines, data quality, or usage information, we knew we could rely on DataHub to understand our data in context.
Also, DataHub’s pre-built integrations with systems like Airflow, Kafka, and others meant that it could be easily integrated into our existing data ecosystem.
Lastly, but importantly, the flexibility it offered meant that we could use it to build additional UI features to support our observability needs.
Solution Implementation
Our implementation involved two steps:
- Building our client to emit Datasets and batch Data Jobs
- Building additional UI features to fill in some of our past observability gaps
Building our client:
We set up our client in order to emit metadata change proposals to DataHub. These metadata change proposal events are then emitted to a Kafka topic where the schema for the event is looked up in the schema registry to help serialize the payload to Kafka. And ultimately, the data is ingested by the DataHub metadata service.


Building additional UI
We also built UI using DataHub for…
Data Job timeliness tracking
For example, below you can see how we set up a Data Job in DataHub for which job owners can set different types of SLAs (both start-by and finish-by in this case).


As you can see above, this page exposes different SLA misses, as well as the latest run for tasks. We also designed the UI to expose additional information, such as the number of runs finished over SLA, the percentage of such runs, and average delays.
Pipeline status tracking
Going back to our ~1000-task UAR as an example, we wanted a dashboard that all runners could visit at the end of each month to track the progress of the pipeline.
This is what our pipeline timeliness dashboard looks like for the UAR pipeline.

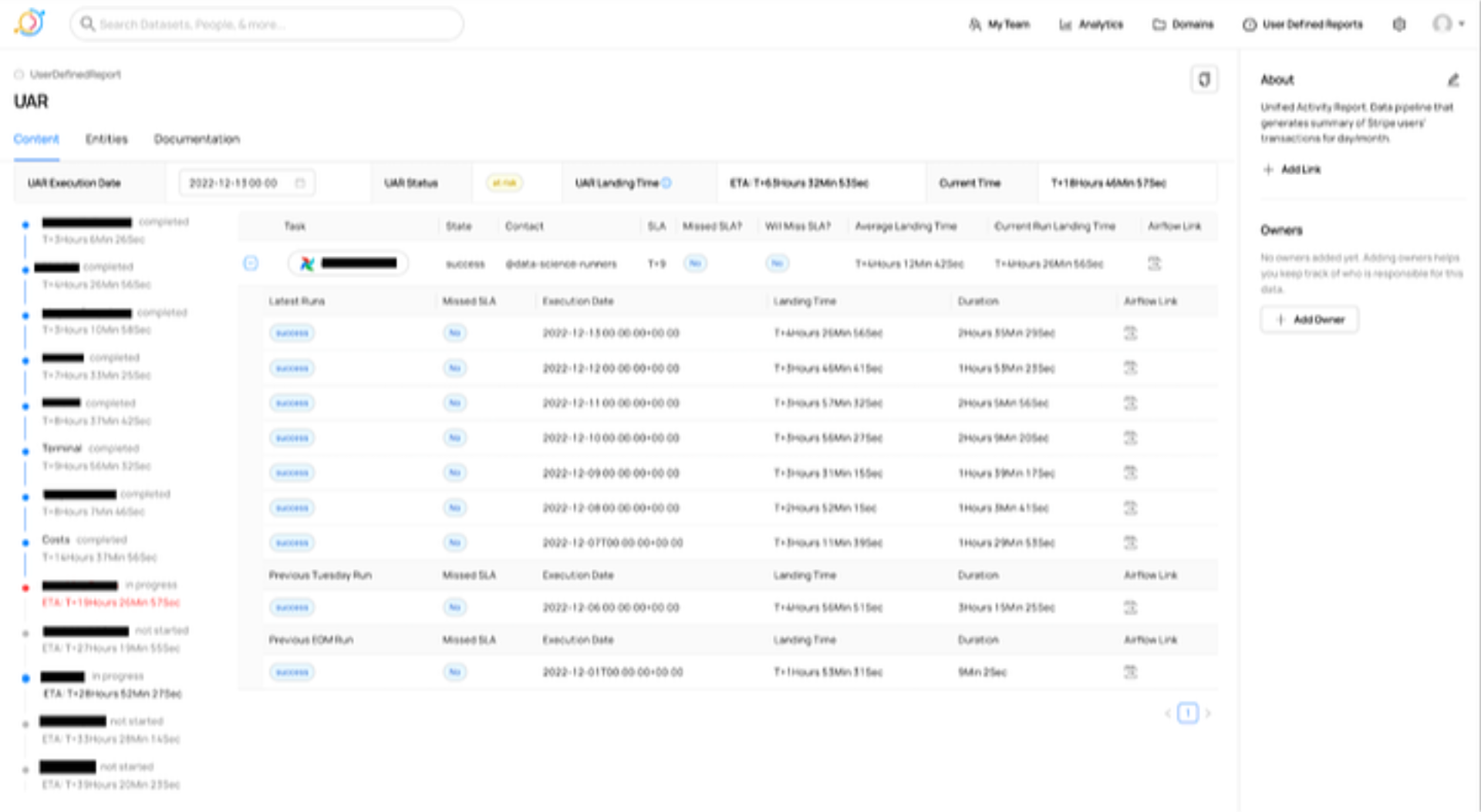
To avoid displaying too many (~1000) tasks in this view, we split up the entire pipeline into segments or logical groupings of tasks (mostly ordered chronologically, owned by different teams) — as seen in the left bar.
Users can choose a specific run to look at, and see the pipeline’s entire status — an estimated landing time, current time, etc. Within each of these tasks, users can click each task to see more metadata (say, the latest task run, whom to contact in case of delays or misses, average landing time, current run landing time) or even to view the task/s in the Airflow UI.
We designed this page to be entirely self-serve; users can use the DataHub UI to add tasks into segments. We use DataHub tags to group tasks into segments, or to add other labels as needed (such as the ‘risky’ tag for tasks attached to say, the critical UAR pipeline).
Team Metrics Page
Many teams rely on creating their own dashboards to track SLA misses, and often don’t know which teams are their main downstream consumers. We wanted to create a view in DataHub for a team to visit and retrieve important information about how their Data Jobs or Datasets are fairing in regards to SLAs and landing times.


We additionally wanted to display any incidents that the team was involved in during the selected time range in order to help teams understand a potential cause for a series of SLA misses, as well as a table displaying the team’s top downstream consuming teams.


SLA observability for critical Data Jobs
We also provided users a self-serve approach to build their own historical SLA-tracking dashboard in DataHub with the flexibility to add critical Data Jobs for visibility.
The image below shows our historical SLA-tracking page for our most critical Data Jobs — with a timeline view and split up by teams.


Outcomes
Today, our data pipeline owners have complete visibility into their pipelines, their performance, and their timeliness.
Instead of having to resort to follow-ups and Slack messages to triage delays, teams know exactly where to go to see their tasks, their dependencies, and how they fare on their SLAs.
Additionally, our leadership team now has easy access to a high-level view of how our platform is performing for our major customers.
What Next
We’ve had a great experience integrating with DataHub to solve our pipeline observability and timeliness challenges. It has proved to be the perfect solution for our needs. We will continue to work with our most prominent data owners and Airflow users to build additional features to help them monitor their Data Jobs.
I’m excited to continue to see everything we can accomplish with DataHub — with and for, the DataHub Community!
Interested in becoming a contributor to the DataHub Blog?
Inspire others and spark meaningful conversations. The DataHub Community is a one-of-a-kind group of data practitioners who are passionate about enabling data discovery, data observability, and federated data governance. We all have so much to learn from one another as we collectively address modern metadata management and data governance; by sharing your perspective and lived experiences, we can create a living repository of lessons learned to propel our Community toward success.
Check out more details on how to become a DataHub Blog Contributor, we can’t wait to speak with you! 👋
Connect with DataHub
Join us on Slack • Sign up for our Newsletter • Follow us on Twitter
Stripe
DataHub
Community
Open Source
Data Engineering

NEXT UP

Governing the Kafka Firehose
Kafka’s schema registry and data portal are great, but without a way to actually enforce schema standards across all your upstream apps and services, data breakages are still going to happen. Just as important, without insight into who or what depends on this data, you can’t contain the damage. And, as data teams know, Kafka data breakages almost always cascade far and wide downstream—wrecking not just data pipelines, and not just business-critical products and services, but also any reports, dashboards, or operational analytics that depend on upstream Kafka data.

When Data Quality Fires Break Out, You're Always First to Know with Acryl Observe
Acryl Observe is a complete observability solution offered by Acryl Cloud. It helps you detect data quality issues as soon as they happen so you can address them proactively, rather than waiting for them to impact your business’ operations and services. And it integrates seamlessly with all data warehouses—including Snowflake, BigQuery, Redshift, and Databricks. But Acryl Observe is more than just detection. When data breakages do inevitably occur, it gives you everything you need to assess impact, debug, and resolve them fast; notifying all the right people with real-time status updates along the way.


John Joyce
2024-04-23

Five Signs You Need a Unified Data Observability Solution
A data observability tool is like loss-prevention for your data ecosystem, equipping you with the tools you need to proactively identify and extinguish data quality fires before they can erupt into towering infernos. Damage control is key, because upstream failures almost always have cascading downstream effects—breaking KPIs, reports, and dashboards, along with the business products and services these support and enable. When data quality fires become routine, trust is eroded. Stakeholders no longer trust their reports, dashboards, and analytics, jeopardizing the data-driven culture you’ve worked so hard to nurture
John Joyce
2024-04-17